Purpose
This article will delineate and explain components of a web application architecture that my company (Relational Data, LLC) uses in order to build broadly-scoped, interactive, ERP-class systems on IBM i.
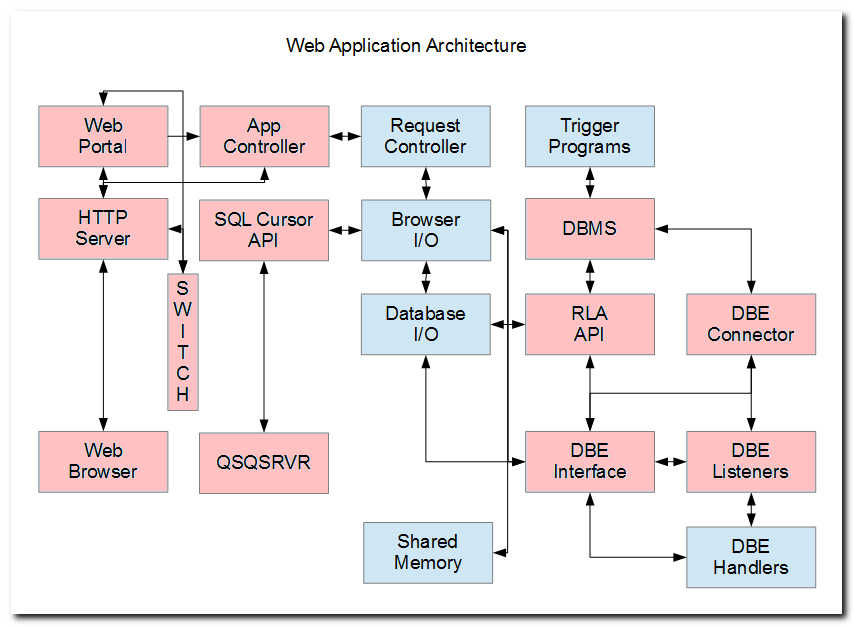
The architecture is depicted in the diagram above. I plan on giving a high-level overview in this piece, then delving deeper into its components, including RPG source code examples in later writings.
Background
It seems that the vast number of articles that explain web-application development, or introduce web-application frameworks and language environments, focus on the basics of receiving requests from browsers and generating formatted responses.
Given the number and variety of servers that implement the HTTP protocol, the number of web-application servers, frameworks, and language environments that are available, it sometimes wearies me to read about yet another interface that implements this basic request-response cycle.
Each framework/language environment promises ease of use. The writings often include rudimentary source-code samples to emphasize the point. They often fill in gaps with promises and assurances that are less than verifiable.
Any web-application framework and language environment will meet simple requirements. But most fail or entail major work-a rounds and significant costs in order to meet the functional requirements of ERP-class systems, or that scale to thousands or tens of thousands of concurrent users. Often, their most distinctive feature is "popularity".
I'm currently working on a proof-of-concept application for an organization that has previously evaluated several web-application tools that were unable to meet their requirements. Given the framework delineated above, I have been able to meet every requirement/wish that has been suggested to date with clear, readable code.
Broadly-scoped systems entail requirements for:
- Adapting to changes in UI and business requirements over time.
- Code that is easy to maintain and extend.
- Modules that implement a separation of concerns.
- Support for principles such as don't-repeat-yourself.
- The implementation of reusable components.
- Programmer productivity.
Subsequent sections in this article briefly delineate the purpose and role of the components (boxes) that are depicted in the diagram above. Future articles in this series will provide more detail.
Web Browser
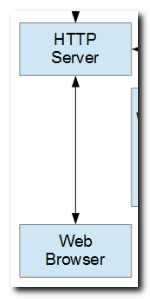
Web browsers are depicted communicating with an HTTP server (IBM i Apache based) in the lower left-hand area of the diagram.
Web browsers have become the de-facto client for requesting and consuming static content that is provided by web servers, and dynamic content provided by applications that are invoked by them.
Although browsers support Javascript in addition to HTML and CSS, the diagram depicted above suggests that servers are better suited to support complex application architecture than browsers. If that's true, one might ask why are there so many Javascript frameworks, and why do web applications download so much Javascript?
Whatever the reason, this series will focus on server architecture as opposed to architecture that may be available via Javascript frameworks.
HTTP Server
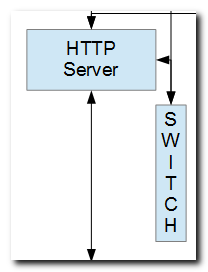
The IBM i Apache-based HTTP server is depicted in this diagram.
Note that the diagram does NOT depict "applications" running within an HTTP server process (eg. CGI). Rather, the HTTP server in this framework is used only for serving static content and handling communications (eg TCP/IP) between browsers and applications.
I would suggest that any interface or framework that combines HTTP communications and applications in a process or any other tightly-bound way will lead to scalability issues as users and uses increases.
Over time, a misbehaving application, or a large number of applications loaded concurrently can kill an HTTP service.
Rather than loading applications into HTTP server jobs, the diagram depicts the HTTP server communicating with a process known as a "switch", which maintains a list of concurrently running applications in its memory, and "informs" HTTP server threads how to communicate with them. Applications may be running as Jobs in various IBM i subsystems.
The switch becomes aware of applications that are launched from the IBM i command line or from a web portal, and sets up channels for them to communicate with HTTP server threads. The switch routes browser requests to the right applications.
This is perhaps the most reliable, scalable, and best performing web-application architecture under IBM i.
Web Portal
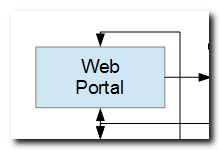
My idea of a web portal is an application that handles functionality that is better housed in one application, and shared by many applications, rather than being incorporated into each. For example:
- User authentication (Login).
- Reset user passwords.
- Manage environments that applications run under (eg. library lists, IFS directories).
- Application definitions (secured options, linked applications).
- Users, user groups, granted authorities.
- Menu system including navigation, favorites.
- Launching and ending application instances.
- Any kind of configuration that might be shared by many applications.
- Toggling between concurrently running applications.
Regarding launching and ending application instances from menus, I'm referring to an interface where users can interact with their own interactive Job, where application and database state is maintained in that Job, as opposed to writing code within applications in order to manage individual sessions for multiple concurrent users.
IBM i manages many concurrent Jobs, arguably much better than any other platform. Interfaces that support that facilitate broadly-scoped functionality.
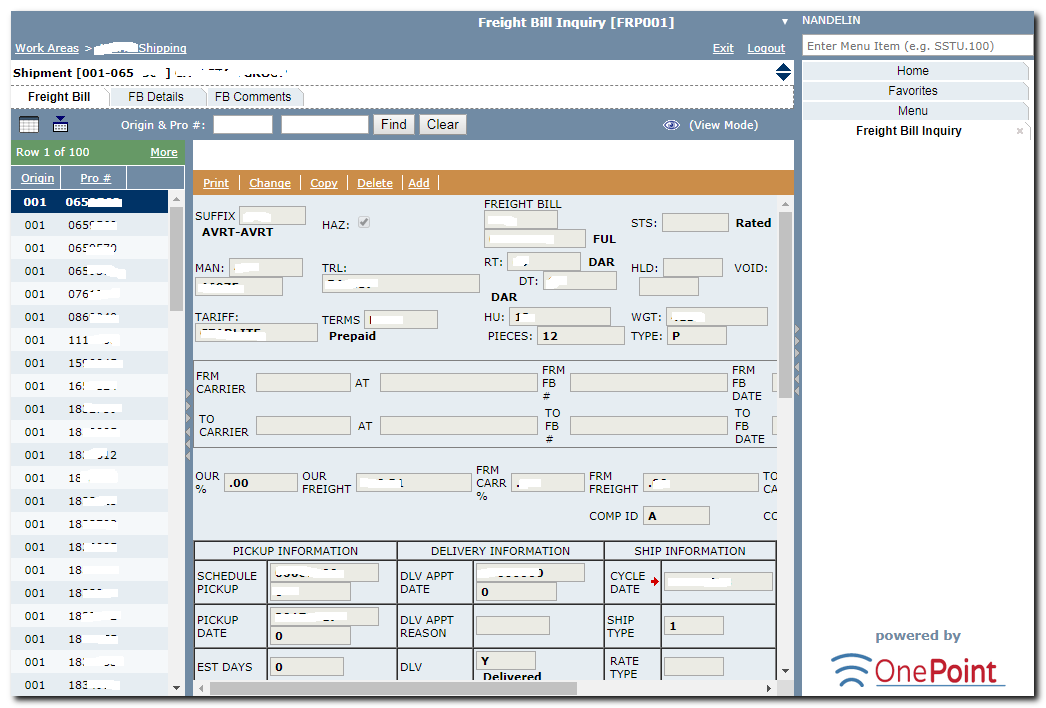
A few screen shots of Onepoint Portal may clarify:
Application Controller
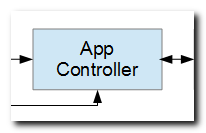
Complex systems might be composed of hundreds or thousands of individual applications. That idea suggests that individual applications would have limited scope. That seems logical, doesn't it?
The last screen-shot (above) depicts a multi-tabbed application (Freight Bill Inquiry), which includes tabs for Freight Bill Details and Freight Bill Comments, which are separate applications for the sake of modularity, but linked to it by means of tabs.
A tab "click" event might send a request to the HTTP server as follows:
http://rd.radile.com/rdweb/apps/avtsh/11JDS12C7589/begin.shtml?rwappid=CAP001
A generic utility known as an "application controller" receives the request and dispatches it to an application by invoking an RPG program named "CAP001" as referenced by the "rwappid" query-string parameter.
The application controller in this case is running under a single-stateful IBM i Job; That Job is supporting just one user. As the user navigates from tab to tab (or by means of other UI events), the application controller would invoke various applications in order to process such requests.
An application controller is a generic utility that may be used to "route" requests to various applications. This facilitates clear, readable, modular code that has well-defined and limited scope.
This section introduces an implementation of an established design pattern known as model-view-controller (MVC). Subsequent sections further delineate our implementation of this design pattern.
Request Controller
Just as application controllers may dispatch requests to applications, a program known as a "request controller" may dispatch requests to bound service-program procedures.
Consider again the URL that was requested by a tab click event.
http://rd.radile.com/rdweb/apps/avtsh/11JDS12C7589/begin.shtml?rwappid=CAP001
In this case the "begin" action is being requested of the "CAP001" program. When "begin" is requested, CAP001 might implement a flow-control structure such as a select-when block that further dispatches the request to a subroutine or bound service-program procedure.
Hence the name "request dispatcher". Program modules that are mostly limited in scope to flow control are quite readable and easy to maintain.
For purposes of modularity, one might limit the scope of "applications" to handle perhaps fewer than a dozen related requests. You might modify that suggestion as circumstances dictate.
Browser I/O Service Program
Browser I/O service programs export a set of procedures that receive input from browsers and generate appropriately formatted responses to requests.
These procedures may follow a specific design pattern such as one established for basic database inquiry and maintenance. Or they might be custom-coded in order to meet unique requirements.
Browser I/O service programs may be bound to other service programs that implement SQL queries, database I/O (service programs that export record-level-access procedures), and other service programs that export data and procedures that may be shared among applications within an IBM i Job.
Shared Memory Service Program

It's common to see hierarchical parent-child relationships in database and application design. One application may maintain "order header" data while another may maintain "order details", etc.
One way to share runtime data between ILE programs and service programs is to bind them to a service program that exports data and data structures that might be required to support hierarchical navigation up and down a tree of individually linked applications.
This is what I refer to as "shared memory service programs". Its a nice way to separate and reduce the complexity of application code, and to keep code in proper context.
SQL Cursor Service Program
An alternative to embedding SQL in HLL programs (eg. ILE RPG), is to use a generic service program that wraps IBM i SQL CLI functions, and exports procedures that are better aligned with ILE RPG interfaces, and that reference SQL views.
One feature of the SQL CLI interface is a configuration option known as "server mode", which causes SQL statements to be run in QSQSRVR pre-start Jobs rather than HLL programs.
This provides a nice separation of SQL code from HLL code and a separation of the SQL language environment from your application environment. It reduces the size of HLL programs and leads to fewer memory requirements.
SQL error handling is encapsulated in the service program, thus eliminating that type of code within HLL programs.
Database I/O Service Program
Database I/O service programs export procedures that roughly correlate with record-level-access operations such as read(), write(), update(), and delete(). But the procedures are application specific as opposed to being merely wrappers around single-file RLA operations.
For example, a read() procedure might return data from a file, plus data from many other files based on foreign-key relationships. write() and update() procedures might invoke data conversion and data validation logic such a converting dates from character format to numeric format and validating values.
The idea is to maintain a separation of concerns between service programs that perform browser I/O vs. ones that perform database I/O, thus making the code more adaptable to changing requirements over time.
Record Level Access
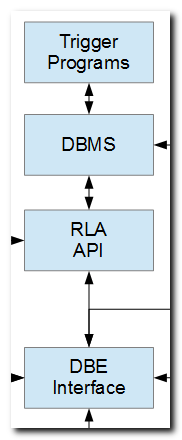
Like the SQL CLI API, another alternative for record-level-access operations is the availability of functions provided by IBM for C programmers. These functions are exported from service program QC2IO, and are used internally by IBM i.
RPG wrappers around QC2IO functions provide a nice way of encapsulating RLA operations plus I/O error handling that may result from DBMS constraints and data validations that may be embedded in trigger programs, which may apply to any file. This streamlines DB I/O procedures in applications.
The acronym in the box labeled "DBE Interface" stands for "database event interface", which is a service program that facilitates I/O and error handling that may occur in connection with read, write, update, and delete events.
Altogether, they provide generic functionality that reduces the amount of I/O related code that would otherwise be required to be embedded in applications.
They provide a nice separation of concerns.
Database Event Handling
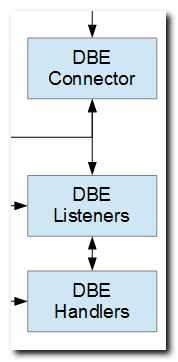
One tenet of database and application modernization is the practice of placing data validation, referential integrity constraints, business rules, and other logic that is incidental to database events into trigger programs.
Notwithstanding, the IBM i trigger interface is somewhat unwieldy. An alternative is an interface that I refer to as "database event handling", which includes additional plumbing that streamlines the programming interface and provides generic functionality such as optional automated logging of database events (read, write, update, and delete).
Rather than writing trigger programs, the plumbing includes a generic trigger program known as a "database event connector" that encapsulates data about database events and forwards it to a pool of "database event listeners" that are running as separate processes. These servers load and invoke procedures that may be encapsulated in "database event handlers".
This architecture solves a number of complaints that are often levied against trigger programs. A pool of "listeners" is more efficient than in-process logic, and provides for optional asynchronous processing that improves the performance of processing that may be incidental to database events. Applications are not required to wait for that type of processing.
Summary
The lines and arrows in the diagram below represent forward and backward communication between processes (in some cases), and between call-stack entries (in other cases). This underscores a high degree of integration in this architecture.
Readers can be assured that this architecture facilitates broadly-scoped web-application development under IBM i. It provides for unprecedented reliability, scalability, and maintainability of applications.